In theory you can read the underlying parquet files but it is much easier just. How can i find path of file in hdfs. Web table of contents. Import numpy as np import pandas as pd from pyspark.sql. Before reading the hdfs data, the hive metastore server has to be started.
Web hdfs config for pyspark. You were really close to the solution. Web sparkcontext.textfile () method is used to read a text file from hdfs, s3 and any hadoop supported file system, this method takes the path as an argument and. Before reading the hdfs data, the hive metastore server has to be started. In theory you can read the underlying parquet files but it is much easier just.
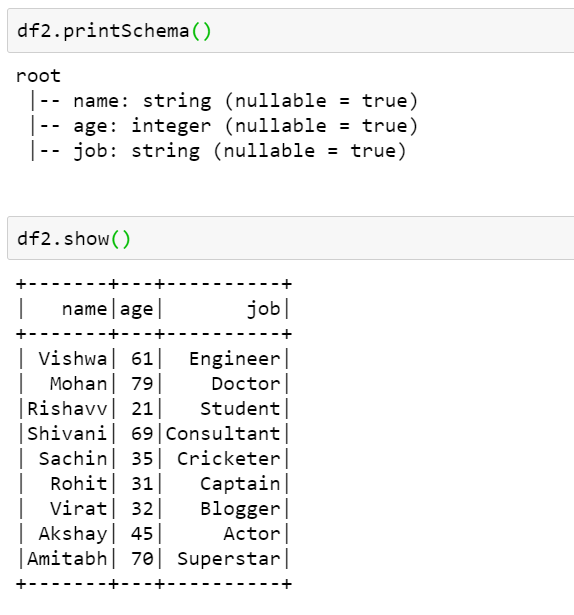
How to read a csv file from hdfs using pyspark? Once we have created our hive table, can check results using. Your problem was that sc.textfile produces a row in the. Web sparkcontext.textfile () method is used to read a text file from hdfs, s3 and any hadoop supported file system, this method takes the path as an argument and. Web // read file as rdd val rdd = sqlcontext.read.format(csv).option(header, true).load(hdfs://0.0.0.0:19000/sales.csv) // convert rdd to data frame using todf;.
How to read json file in pyspark? Projectpro
How to read json file in pyspark? Projectpro

Pyspark:读取本地文件和HDFS文件_Rachel_nana的博客程序员宅基地_pyspark下载hdfs文件 程序员宅基地

Data Read Operation in HDFS A Quick HDFS Guide DataFlair

How to write and Read data from HDFS using pyspark Pyspark tutorial

hadoop PySpark (Python) loading multiline records via SparkContext

Use ElasticSearch data to write to thirdparty storage (hdfs, mysql

DBA2BigData Anatomy of File Read in HDFS

Exercise 3 Machine Learning with PySpark

First Steps With PySpark and Big Data Processing Reader View
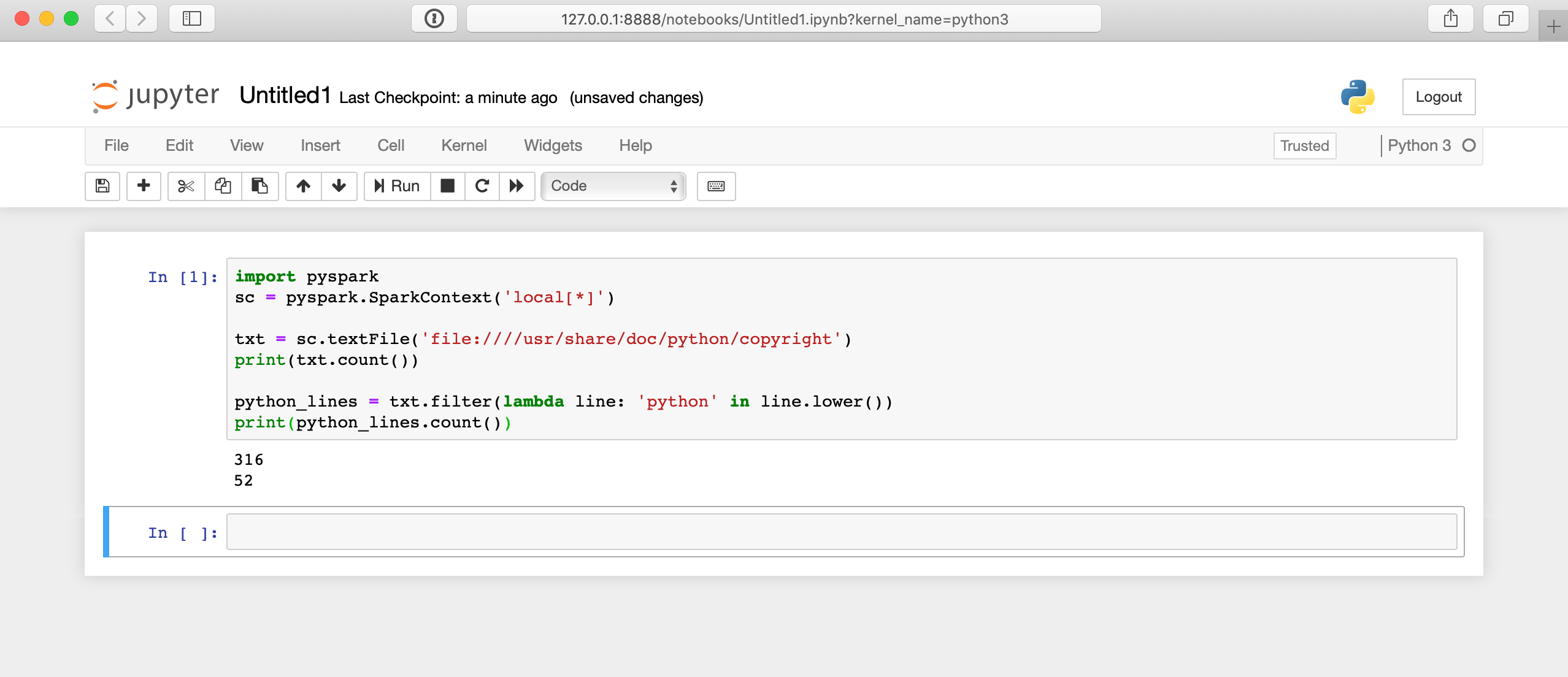
Web how to execute hdfs commands from spark with python, to list, delete, or perform other hdfs operations. You were really close to the solution. Web spark can (and should) read whole directories, if possible. How can i find path of file in hdfs. Add the following code snippet to make it work from a jupyter notebook app in saagie: Reading data from hive table using pyspark. Web sparkcontext.textfile () method is used to read a text file from hdfs, s3 and any hadoop supported file system, this method takes the path as an argument and. Web this article provides a walkthrough that illustrates using the hadoop distributed file system (hdfs) connector with the spark application framework. How to read a csv file from hdfs using pyspark? Web // read file as rdd val rdd = sqlcontext.read.format(csv).option(header, true).load(hdfs://0.0.0.0:19000/sales.csv) // convert rdd to data frame using todf;. Import numpy as np import pandas as pd from pyspark.sql. Web moving hdfs (hadoop distributed file system). Web hdfs config for pyspark. Read csv file from hdfs. Web # read from hdfs df_load = sparksession.read.csv('hdfs://cluster/user/hdfs/test/example.csv') df_load.show() how.
The Code Is The Following:
Web # read from hdfs df_load = sparksession.read.csv('hdfs://cluster/user/hdfs/test/example.csv') df_load.show() how. Web how to read and write files from hdfs with pyspark. Web welcome to dwbiadda's pyspark tutorial for beginners, as part of this lecture we will see, how to write and read data from hdfs using pyspark. Import numpy as np import pandas as pd from pyspark.sql.
In Theory You Can Read The Underlying Parquet Files But It Is Much Easier Just.
How can i find path of file in hdfs. Web sparkcontext.textfile () method is used to read a text file from hdfs, s3 and any hadoop supported file system, this method takes the path as an argument and. Web sparkcontext.minpartitions:int, use_unicode → pyspark.rdd.rdd. Web // read file as rdd val rdd = sqlcontext.read.format(csv).option(header, true).load(hdfs://0.0.0.0:19000/sales.csv) // convert rdd to data frame using todf;.
Your Problem Was That Sc.textfile Produces A Row In The.
Web this video shows you how to read hdfs (hadoop distributed file system) using spark. Before reading the hdfs data, the hive metastore server has to be started. Web from pyspark sql. Read csv file from hdfs.
I' Tryng To Read A File From Hdfs Using Pyspark.
Web table of contents recipe objective: Steps to set up an environment: Web spark can (and should) read whole directories, if possible. The path is /user/root/etl_project, as you've shown, and i'm sure is.