Web and i have no explanation why everything worked with the same data types, but from 23 times refuses to work correctly. Parameter ‘chunksize’ supports optionally iterating or breaking of the file into chunks. Web using pandas.read_csv (chunksize) one way to process large files is to read the entries in chunks of reasonable size, which are read into the memory and are. Web use the pandas.read_csv() method to read the file. Web what is the optimal chunksize in pandas read_csv to maximize speed?
Set the chunksize argument to the number of rows each chunk should contain. Additional help can be found in the online. Manually chunking is an ok option for workflows that don’t require. Web use the pandas.read_csv() method to read the file. Web 1 i need to read a large 4gb file as csv in pandas into a dataframe.
The string could be a url. I realized that pandas.read_csv has a parameter called chunksize! Web doesn't work so i found iterate and chunksize in a similar post so i used: Ask question asked 7 years, 9 months ago modified 3 years, 11 months ago viewed 15k times 13 i. Df = pd.read_csv ('check1_900.csv', sep='\t', iterator=true, chunksize=1000) all good, i.
Read and Process large csv / dbf files using pandas chunksize option in

pandas read_csv with chunksize Stack Overflow

Pandas Read Multiple CSV Files into DataFrame Spark by {Examples}

How To Read Csv File In Pandas Using Python Csv File Using Pandas

Exercise1 How to read CSV using pandas? YouTube

Pandas read_csv() with Examples Spark By {Examples}

26. How to Read A Large CSV File In Chunks With Pandas And Concat Back

Pandas DataFrame Read CSV Example YouTube

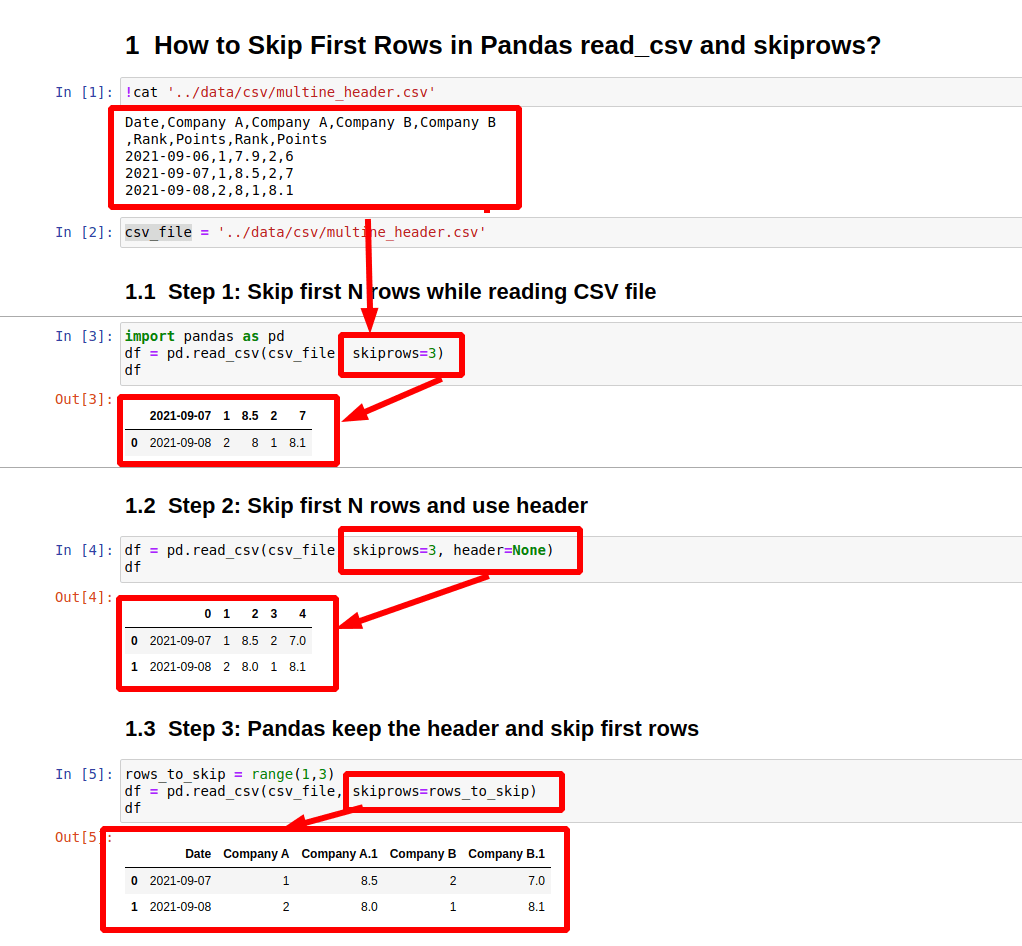
How to Skip First Rows in Pandas read_csv and skiprows?
Introduction to Pandas (Part2) Reading CSV Files YouTube

Also supports optionally iterating or breaking of the file into chunks. Web doesn't work so i found iterate and chunksize in a similar post so i used: Web as an alternative to reading everything into memory, pandas allows you to read data in chunks. Start = time.time () df = pd.read_csv ('huge_data.csv') end = time.time. Manually chunking is an ok option for workflows that don’t require. Import pandas as pd data=pd.read_table('datafile.txt',sep='\t',chunksize=1000) for. Parameter ‘chunksize’ supports optionally iterating or breaking of the file into chunks. It runs for a few. I realized that pandas.read_csv has a parameter called chunksize! Additional help can be found in the online. Web internally dd.read_csv uses pandas.read_csv() and supports many of the same keyword arguments with the same performance guarantees. Web pandas ‘read_csv’ method gives a nice way to handle large files. Df = pd.read_csv ('check1_900.csv', sep='\t', iterator=true, chunksize=1000) all good, i. Import pandas as pd import glob #get files. Web using pandas.read_csv (chunksize) one way to process large files is to read the entries in chunks of reasonable size, which are read into the memory and are.
It Runs For A Few.
The string could be a url. Web and i have no explanation why everything worked with the same data types, but from 23 times refuses to work correctly. Web doesn't work so i found iterate and chunksize in a similar post so i used: Iterate over the rows of.
Set The Chunksize Argument To The Number Of Rows Each Chunk Should Contain.
Web what is the optimal chunksize in pandas read_csv to maximize speed? In the case of csv, we can load only some of the lines into memory. I realized that pandas.read_csv has a parameter called chunksize! Web i'm trying to read a big size csv file using pandas that will not fit in the memory and create word frequency from it, my code works when the whole file fits inside.
Web Internally Dd.read_Csv Uses Pandas.read_Csv() And Supports Many Of The Same Keyword Arguments With The Same Performance Guarantees.
Additional help can be found in the online. Parameter ‘chunksize’ supports optionally iterating or breaking of the file into chunks. Web 1 hour agoi have a bunch of csv files from an hplc, when doing a standard import via pandas.read_csv i get something like this. Web i am trying to extract certain rows from a 10gb ~35mil rows csv file into a new csv based on condition (value of a column (geography = ontario)).
Web Here Comes The Good News And The Beauty Of Pandas:
Df = pd.read_csv ('check1_900.csv', sep='\t', iterator=true, chunksize=1000) all good, i. Manually chunking is an ok option for workflows that don’t require. Start = time.time () df = pd.read_csv ('huge_data.csv') end = time.time. Web use the pandas.read_csv() method to read the file.