For example, if i have a 13 column file, i can do usecols= [0,1,.,10,11]. Web usecols argument is parsed in parsers.py in function def _validate_usecols_arg(usecols). Web i have a csv file, is it possible to have usecols take all columns except the last one when utilizing read_csv without listing every column needed. Use usecols with column names df = pd.read_csv('my_data.csv', usecols= ['this_column', 'that_column']) method 2: Use usecols with column names df = pd.read_csv('my_data.csv', usecols= ['this_column', 'that_column']) method 2:
Use efficient datatypes# the default pandas. Not all file formats that can be read by pandas provide an option to read a subset of columns. Read_csv (filepath_or_buffer, sep=, delimiter=none, header='infer', names=none, index_col=none, usecols=none, squeeze=false, prefix=none, mangle_dupe_cols=true, dtype=none, engine=none, converters=none, true_values=none, false_values=none, skipinitialspace=false, skiprows=none, skipfooter=0, nrows=none,. Cols_to_use = [0,1,5,16,8] df_ret = pd.read_csv (filepath, index_col=false, usecols=cols_to_use) the trouble is df_ret contains the correct columns, but not in the order i specified. Read_csv (filepath_or_buffer, *, sep = _nodefault.no_default, delimiter = none, header = 'infer', names = _nodefault.no_default, index_col = none, usecols = none, dtype = none, engine = none, converters = none, true_values = none, false_values = none, skipinitialspace = false, skiprows = none, skipfooter = 0, nrows = none, na_values.
Use usecols with column positions df = pd.read_csv('my_data.csv', usecols= [0, 2]) the following examples show how to use each method in practice with the following csv file called basketball_data.csv: Import pandas as pd df = pd.read_csv('df.csv', header=0,usecols=[ab, cd, ij]) this is what i'd like to get: Not all file formats that can be read by pandas provide an option to read a subset of columns. This function returns set(usecols) so the dupe column is removed by design. If you think about it, that makes sense, as a good practice should be to parse once the columns of interest, and then reindex_axis(['c', 'd', 'c', axis=1) for i/o and.
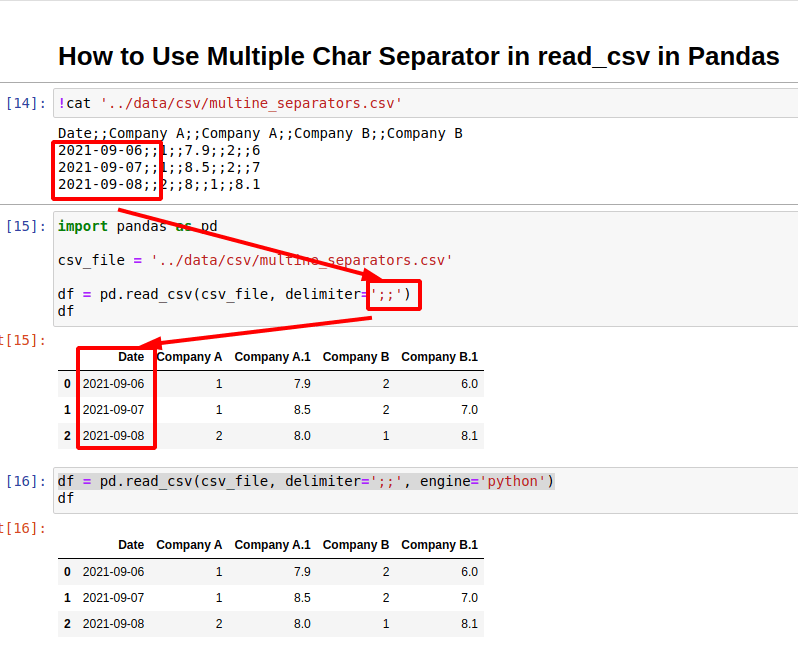
How to Use Multiple Char Separator in read_csv in Pandas
Pandas Read CSV Tutorial skiprows, usecols, missing data + more YouTube

Exercise1 How to read CSV using pandas? YouTube

Pandas Read Multiple CSV Files into DataFrame Spark by {Examples}

How To Read Csv File In Pandas Using Python Csv File Using Pandas

pandas.read_csv中的usecols函数实现读取指定列_baiduliuming的博客程序员宅基地_pandas

Read CSV File as pandas DataFrame in Python (5 Examples) (2022)
Pandas read_csv() with Examples Spark By {Examples}

Selecting columns when reading a CSV into pandas YouTube

How to read CSV File into Python using Pandas by Barney H. Towards
Not all file formats that can be read by pandas provide an option to read a subset of columns. If you think about it, that makes sense, as a good practice should be to parse once the columns of interest, and then reindex_axis(['c', 'd', 'c', axis=1) for i/o and. Use usecols with column names df = pd.read_csv('my_data.csv', usecols= ['this_column', 'that_column']) method 2: Web with pandas.read_csv(), you can specify usecols to limit the columns read into memory. Web i am using pandas read_csv function to pull in a subset of these columns, using the usecols parameter to choose the ones i want: So because you have a header row, passing header=0 is sufficient and additionally passing names appears to be confusing pd.read_csv. Web i have a csv file, is it possible to have usecols take all columns except the last one when utilizing read_csv without listing every column needed. I'm using pandas 0.17 python pandas share Use usecols with column positions df = pd.read_csv('my_data.csv', usecols= [0, 2]) the following examples show how to use each method in practice with the following csv file. If used properly, there should never be a need to delete columns after reading. Cols_to_use = [0,1,5,16,8] df_ret = pd.read_csv (filepath, index_col=false, usecols=cols_to_use) the trouble is df_ret contains the correct columns, but not in the order i specified. Web usecols is supposed to provide a filter before reading the whole dataframe into memory; For example, if i have a 13 column file, i can do usecols= [0,1,.,10,11]. Use usecols with column positions df = pd.read_csv('my_data.csv', usecols= [0, 2]) the following examples show how to use each method in practice with the following csv file called basketball_data.csv: Read_csv (filepath_or_buffer, *, sep = _nodefault.no_default, delimiter = none, header = 'infer', names = _nodefault.no_default, index_col = none, usecols = none, dtype = none, engine = none, converters = none, true_values = none, false_values = none, skipinitialspace = false, skiprows = none, skipfooter = 0, nrows = none, na_values.
Web I Am Using Pandas Read_Csv Function To Pull In A Subset Of These Columns, Using The Usecols Parameter To Choose The Ones I Want:
If you think about it, that makes sense, as a good practice should be to parse once the columns of interest, and then reindex_axis(['c', 'd', 'c', axis=1) for i/o and. Use usecols with column positions df = pd.read_csv('my_data.csv', usecols= [0, 2]) the following examples show how to use each method in practice with the following csv file called basketball_data.csv: Use usecols with column names df = pd.read_csv('my_data.csv', usecols= ['this_column', 'that_column']) method 2: So because you have a header row, passing header=0 is sufficient and additionally passing names appears to be confusing pd.read_csv.
Import Pandas As Pd Df = Pd.read_Csv('Df.csv', Header=0,Usecols=[Ab, Cd, Ij]) This Is What I'd Like To Get:
Web i have a csv file, is it possible to have usecols take all columns except the last one when utilizing read_csv without listing every column needed. Use usecols with column positions df = pd.read_csv('my_data.csv', usecols= [0, 2]) the following examples show how to use each method in practice with the following csv file. Not all file formats that can be read by pandas provide an option to read a subset of columns. If used properly, there should never be a need to delete columns after reading.
I'm Using Pandas 0.17 Python Pandas Share
Web usecols argument is parsed in parsers.py in function def _validate_usecols_arg(usecols). Read_csv (filepath_or_buffer, sep=, delimiter=none, header='infer', names=none, index_col=none, usecols=none, squeeze=false, prefix=none, mangle_dupe_cols=true, dtype=none, engine=none, converters=none, true_values=none, false_values=none, skipinitialspace=false, skiprows=none, skipfooter=0, nrows=none,. Cols_to_use = [0,1,5,16,8] df_ret = pd.read_csv (filepath, index_col=false, usecols=cols_to_use) the trouble is df_ret contains the correct columns, but not in the order i specified. Web with pandas.read_csv(), you can specify usecols to limit the columns read into memory.
Read_Csv (Filepath_Or_Buffer, *, Sep = _Nodefault.no_Default, Delimiter = None, Header = 'Infer', Names = _Nodefault.no_Default, Index_Col = None, Usecols = None, Dtype = None, Engine = None, Converters = None, True_Values = None, False_Values = None, Skipinitialspace = False, Skiprows = None, Skipfooter = 0, Nrows = None, Na_Values.
For example, if i have a 13 column file, i can do usecols= [0,1,.,10,11]. Use efficient datatypes# the default pandas. Web usecols is supposed to provide a filter before reading the whole dataframe into memory; This function returns set(usecols) so the dupe column is removed by design.