Reading partitioned data from s3. Web import pyarrow as pa import pyarrow.parquet as pq fs = pa.hdfs.connect(self.namenode, self.port, user=self.username, kerb_ticket = self.cert) i'm. Failed to open local file 's3://bucket1/0001.csv', error: If a string passed, can be a single file name or directory name. For more on what’s in the 14.0.0 r package, see the r.
Use existing metadata object, rather than reading from file. Web parallelization frameworks for pandas increase s3 reads by 2x. For more on what’s in the 14.0.0 r package, see the r. Web the character delimiting individual cells in the csv data. Web optimized reading with predicate pushdown (filtering rows), projection (selecting and deriving columns), and optionally parallel reading.
Web this is throwing error errormessage: Web typically this is done by prepending a protocol like s3:// to paths used in common data access functions like dd.read_csv: Local fs ( localfilesystem) s3 ( s3filesystem) google cloud storage file system (. Web import pyarrow as pa import pyarrow.parquet as pq fs = pa.hdfs.connect(self.namenode, self.port, user=self.username, kerb_ticket = self.cert) i'm. Web the character delimiting individual cells in the csv data.
python Pyarrow is slower than pandas for csv read in Stack Overflow

Three ways to read CSV data into Python YouTube

Use Pandas 2.0 with PyArrow Backend to read CSV files faster YouTube

[Solved] Reading csv from S3 and inserting into a MySQL 9to5Answer
![[Solved] Reading csv from S3 and inserting into a MySQL 9to5Answer](https://i2.wp.com/sgp1.digitaloceanspaces.com/ffh-space-01/9to5answer/uploads/post/avatar/283889/template_reading-csv-from-s3-and-inserting-into-a-mysql-table-with-aws-lambda20220613-1532174-1nzlwuh.jpg)
How to read/parse CSV files in Node.js with examples W.M. (2023)

Using pyarrow to read S3 parquet files from Lambda 9to5Tutorial

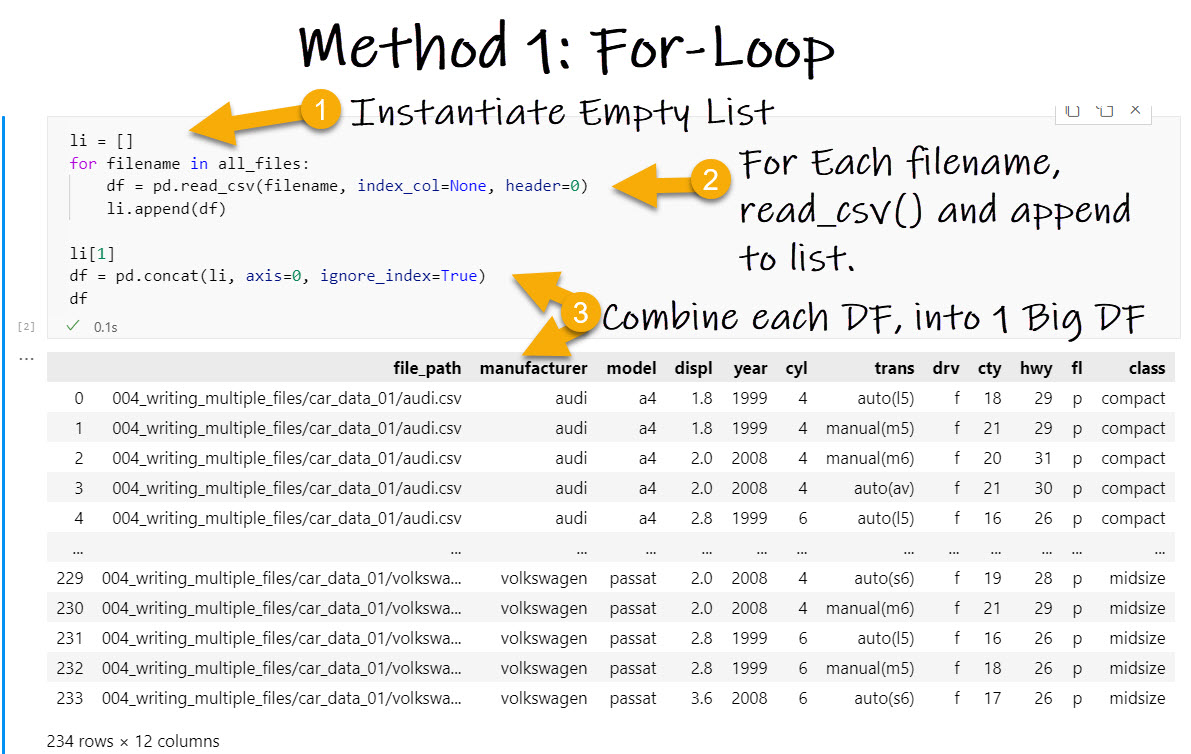
3 Ways to Read Multiple CSV Files ForLoop, Map, List Comprehension
Reading csv from Python in S3 into a dataframe 9to5Tutorial

python Using Pyarrow to read parquet files written by Spark increases

PyArrow vs. Pandas for managing CSV files How to Speed Up Data

The documentation page of pyarrow.csv.read_csv says. If a string passed, can be a single file name or directory name. Web parallelization frameworks for pandas increase s3 reads by 2x. Web read csv file (s) from a received s3 prefix or list of s3 objects paths. The character used optionally for escaping. Web class pyarrow.fs.s3filesystem(access_key=none, *, secret_key=none, session_token=none, bool anonymous=false, region=none, request_timeout=none,. Web optimized reading with predicate pushdown (filtering rows), projection (selecting and deriving columns), and optionally parallel reading. In this short guide you’ll see how to read and write parquet files. Pyarrow.csv.read_csv(input_file, read_options=none, parse_options=none, convert_options=none, memorypool memory_pool=none) #. For more on what’s in the 14.0.0 r package, see the r. If a string or path,. Additional help can be found in the online. Web import pyarrow as pa import pyarrow.parquet as pq fs = pa.hdfs.connect(self.namenode, self.port, user=self.username, kerb_ticket = self.cert) i'm. Asked 5 years, 2 months ago. Any valid string path is acceptable.
It Is Immutable And So We Must Find A Way Of Reading It Given The Following Complexities.
Web read csv file (s) from a received s3 prefix or list of s3 objects paths. Web overwrite parquet file with pyarrow in s3. Local fs ( localfilesystem) s3 ( s3filesystem) google cloud storage file system (. Web import pyarrow as pa import pyarrow.parquet as pq fs = pa.hdfs.connect(self.namenode, self.port, user=self.username, kerb_ticket = self.cert) i'm.
The String Could Be A Url.
Import awswrangler as wr df =. Will be used in reads for. Web instead of dumping the data as csv files or plain text files, a good option is to use apache parquet. Also supports optionally iterating or breaking of the file into chunks.
Web Optimized Reading With Predicate Pushdown (Filtering Rows), Projection (Selecting And Deriving Columns), And Optionally Parallel Reading.
Web yes, you can do this with pyarrow as well, similarly as in r, using the pyarrow.dataset submodule (the pyarrow.csv submodule only exposes functionality for. Import dask.dataframe as dd df =. No such file or directory, i know we can read csv file. Whether two quotes in a quoted csv value denote a single quote in the data.
Reading Partitioned Data From S3.
Use existing metadata object, rather than reading from file. Web class pyarrow.fs.s3filesystem(access_key=none, *, secret_key=none, session_token=none, bool anonymous=false, region=none, request_timeout=none,. Pyarrow.csv.read_csv(input_file, read_options=none, parse_options=none, convert_options=none, memorypool memory_pool=none) #. Web 17 hours agoi am trying to improve speed of read_csv() then later dataframe using pandas 2.
