Web to read a json file using pyspark, you can use the read.json () method: Val df:dataframe = spark.read.text(hdfs://nn1home:8020/text01.txt) val ds:dataset[string]. Web 4 i have a dataframe with 1000+ columns. Web from pyspark import sparkcontext, sparkconf conf = sparkconf ().setappname (myfirstapp).setmaster (local) sc = sparkcontext (conf=conf) textfile. Web spark sql provides spark.read.text('file_path') to read from a single text file or a directory of files as spark dataframe.
Web to make it simple for this pyspark rdd tutorial we are using files from the local system or loading it from the python list to create rdd. Web using read.json (path) or read.format (json).load (path) you can read a json file into a pyspark dataframe, these methods take a file path as an argument. Spark sql provides spark.read ().text (file_name) to read a file or directory of text files into a spark dataframe, and dataframe.write ().text (path) to write to a text. Web to read a json file using pyspark, you can use the read.json () method: Val df:dataframe = spark.read.text(hdfs://nn1home:8020/text01.txt) val ds:dataset[string].
Spark sql provides spark.read ().text (file_name) to read a file or directory of text files into a spark dataframe, and dataframe.write ().text (path) to write to a text. This article shows you how to read apache. Web 4 i have a dataframe with 1000+ columns. Val df:dataframe = spark.read.text(hdfs://nn1home:8020/text01.txt) val ds:dataset[string]. Web from pyspark import sparkcontext, sparkconf conf = sparkconf ().setappname (myfirstapp).setmaster (local) sc = sparkcontext (conf=conf) textfile.
Exercício 3 Aprendizado por Máquina com o PySpark

First Steps With PySpark and Big Data Processing Reader View
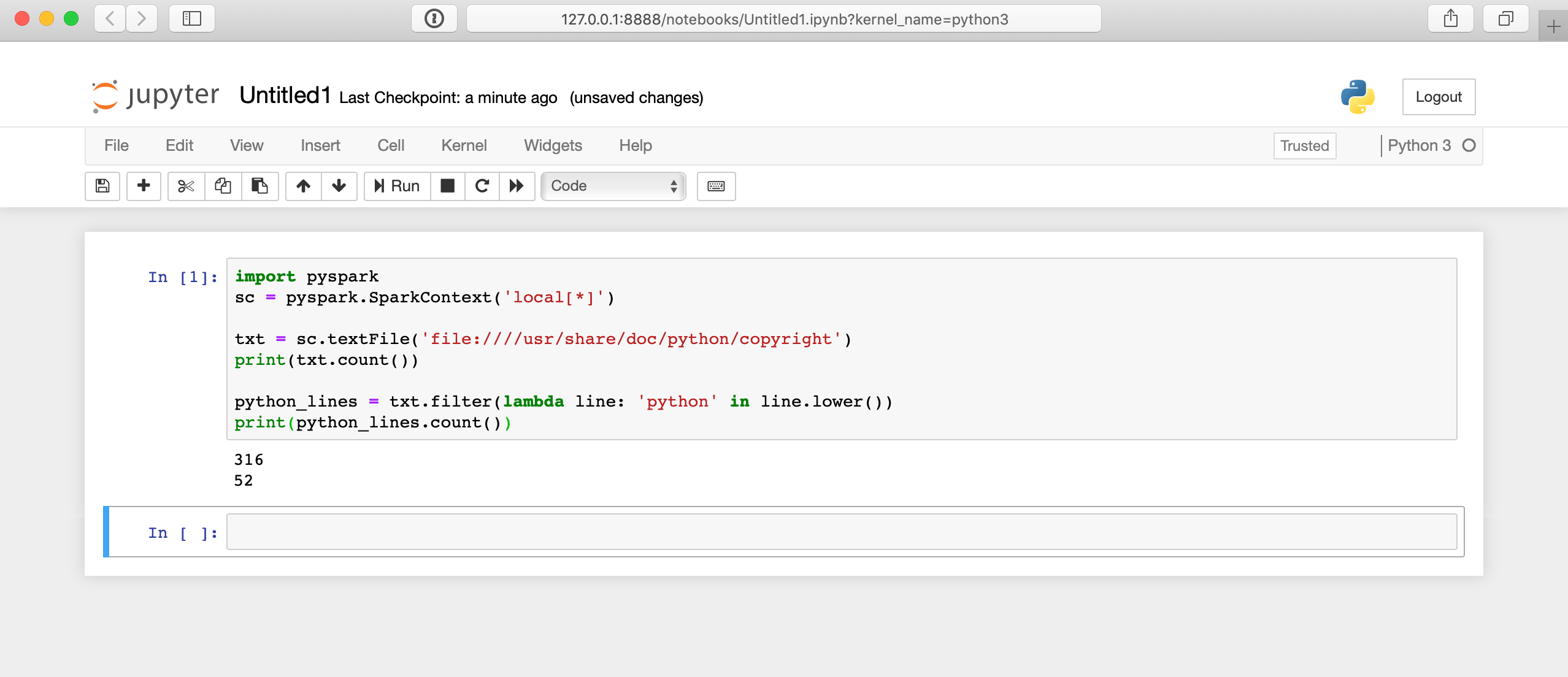
PySpark Read JSON file into DataFrame Reading writing, Reading, Learn

Spark Essentials — How to Read and Write Data With PySpark Reading

3. How to read write csv file in PySpark Databricks Tutorial

3. Read CSV file in to Dataframe using PySpark YouTube

PySpark Tutorial 10 PySpark Read Text File PySpark with Python YouTube

How to write dataframe to text file in pyspark? Projectpro

How to read Single and MultiLine json files using Pyspark YouTube

Pysparkreadcsvoptions VERIFIED

Web to read a json file using pyspark, you can use the read.json () method: Spark sql provides spark.read ().text (file_name) to read a file or directory of text files into a spark dataframe, and dataframe.write ().text (path) to write to a text. Web sparkcontext.textfile(name, minpartitions=none, use_unicode=true) [source] ¶. Web when i read it in, and sort into 3 distinct columns, i return this (perfect): Pyspark provides csv (path) on dataframereader to read a csv file into pyspark dataframe and dataframeobj.write.csv (path) to save or write to the csv. Read a text file from hdfs, a local file system (available on all nodes), or any hadoop. Sample file in my local system ( windows ). Web spark sql provides spark.read.text('file_path') to read from a single text file or a directory of files as spark dataframe. Web to make it simple for this pyspark rdd tutorial we are using files from the local system or loading it from the python list to create rdd. When i read these files into dataframes individually i can see the output. Web 5 rows spark provides several ways to read.txt files, for example, sparkcontext.textfile() and. Val df:dataframe = spark.read.text(hdfs://nn1home:8020/text01.txt) val ds:dataset[string]. I need to save this dataframe as.txt file (not as.csv) with no header,mode should be append used below command. Web using apache spark (or pyspark) i can read/load a text file into a spark dataframe and load that dataframe into a sql db, as follows: Json_file = path/to/your/json/file.json df_json = spark.read.json(json_file) you can write the data.
Read A Text File From Hdfs, A Local File System (Available On All Nodes), Or Any Hadoop.
Web 5 rows spark provides several ways to read.txt files, for example, sparkcontext.textfile() and. Web here , we will see the pyspark code to read a text file separated by comma ( , ) and load to a spark data frame for your analysis. This article shows you how to read apache. Spark read all text files from a directory into a single rdd in spark, by inputting path of the directory to the textfile () method reads all text files and creates a.
When I Read These Files Into Dataframes Individually I Can See The Output.
Spark sql provides spark.read ().text (file_name) to read a file or directory of text files into a spark dataframe, and dataframe.write ().text (path) to write to a text. Web if you wanted to read a text file from an hdfs into dataframe. Web 4 i have a dataframe with 1000+ columns. Web sparkcontext.textfile(name, minpartitions=none, use_unicode=true) [source] ¶.
Web Using Apache Spark (Or Pyspark) I Can Read/Load A Text File Into A Spark Dataframe And Load That Dataframe Into A Sql Db, As Follows:
Json_file = path/to/your/json/file.json df_json = spark.read.json(json_file) you can write the data. Web aug 18 pyspark offers the functionality of using csv (path) through dataframereader to ingest csv files into a pyspark dataframe. Web these are 2 files with same schema but in two different locations on local machine. Web using read.json (path) or read.format (json).load (path) you can read a json file into a pyspark dataframe, these methods take a file path as an argument.
Sample File In My Local System ( Windows ).
Web spark sql provides spark.read.text('file_path') to read from a single text file or a directory of files as spark dataframe. Web when i read it in, and sort into 3 distinct columns, i return this (perfect): Web from pyspark import sparkcontext, sparkconf conf = sparkconf ().setappname (myfirstapp).setmaster (local) sc = sparkcontext (conf=conf) textfile. Web to read a json file using pyspark, you can use the read.json () method: